Below you will find instructions on filling out the dataset form.
Mandatory fields are marked with an asterisk *
Content
- Organizational maintenance rights to metadata
- Datasource
- Lisense and Access Type
- Title, Desciption and other basic information
- Actors
- Related publications and other material
- Geographical Area (spatial coverage)
- Time Period (temporal coverage)
- Infrastructure
- History and events (provenience)
- Project and Funding
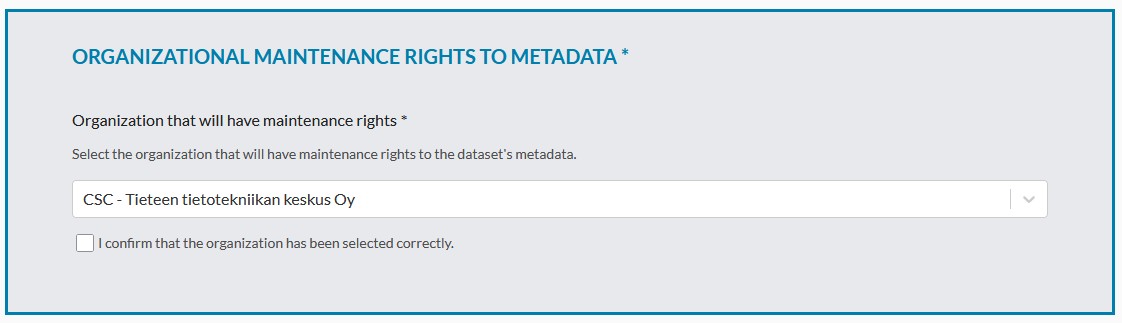
ORGANIZATIONAL MAINTENANCE RIGHTS TO METADATA *
Before starting the actual dataset description, select which organization will have administrator rights to the metadata. By default, your home organization is suggested as the administrator, but you can change it if you wish. Confirm the selection with the checkbox “I confirm that the organization has been selected correctly”.
The administrator’s rights are limited to the dataset metadata and to how the data stored in the IDA service and linked to the description is displayed and made available in Etsin. The administrator can add and edit file-specific metadata in Qvain for files already linked to the dataset and stored in IDA, but cannot add or remove data stored in IDA from the dataset description unless they have project membership in the CSC project that contains the data.
The administrator can also view dataset descriptions in draft status and publish them if needed. The administrator can also delete a dataset description that has already been published.
DATASOURCE *
Before you can attach files to your dataset, you must select whether you are attaching files from IDA or whether you enter the URLs of the external service via which the files can be obtained. The selection is made by selecting either “IDA” or “Remote resources”.

You must select a data source, even if you don’t attach any data to the dataset description.
- If you do not plan to attach data to this dataset description now or in the future, you can choose either data source. Note: A DOI can only be issued if you select IDA as the data source.
- If you’re unsure whether you might add IDA files to the dataset in the future, it’s recommended to choose IDA just in case.
The data source cannot be changed after publication. If you’ve already published your dataset description but want to change the data source, you’ll need to create a new dataset, select the correct data source. You can link the two datasets using the “Related other material” fields in Qvain.
Fairdata IDA files
If you attach files to your dataset from the IDA service, first select a project in IDA. You will then see all frozen files and folders for the project. Select the files and folders you want to attach to your dataset. If you select a folder, all files and subfolders in that folder will be attached to the dataset. Files can be attached to a dataset from only one IDA project. These selected files can be downloaded via Etsin after the dataset is published, unless there are restrictions on downloading the files under “Access type”. NB! Unfreezing or deleting frozen files in IDA will immediately and permanently deprecate all datasets to which those files are attached. Deprecated dataset is still visible in Etsin but data cannot be accessed any more. A warning is presented in IDA if an unfreeze or delete action will deprecate any datasets.
Deprecation cannot be reversed (e.g., by freezing the file again). Below is an example of how you can proceed:
- Fix the files in IDA by re-freezing the desired files or uploading new files to IDA and freezing them
- Create a new version of the dataset description in Qvain (see instructions)
- Attach the desired files to the new version of the dataset description and publish it
- After publishing, both the deprecated version (without access to files) and the new version will be visible in Etsin
- You may choose to delete the deprecated version, but please note that the deleted version can still be accessed in Etsin via its direct PID reference, but it will no longer be visible in Etsin Search nor in Qvain after deletion. If you want to explain why a dataset version was deleted, add that information to the version’s description before deleting it.
DOI identifier
If you attach files from IDA, you can ask a URN identifier to be generated for your dataset (as a default a DOI is generated). Once you have selected IDA as the data source, a checkbox will appear, which is ticked by default (you will get a DOI) for your dataset. By un-ticking the checkbox, you will get a URN instead. This identifier is automatically generated when you publish your dataset. A DOI identifier will begin to resolve (act as a link in http format) to your dataset right after the dataset’s publication and a URN will begin to resolve the day after publication.
Cumulative dataset
A cumulative dataset is a dataset to which files are to be added after the dataset has been published. When a dataset is marked as cumulative, files can be added to it after publication without the need to create a new version of the dataset with a new identifier.
Cumulative datasets are clearly marked in Etsin and thus users are able to consider the nature of the dataset when referring to it.
NB! Files cannot be deleted from a cumulative dataset after publication.
Remote Resources
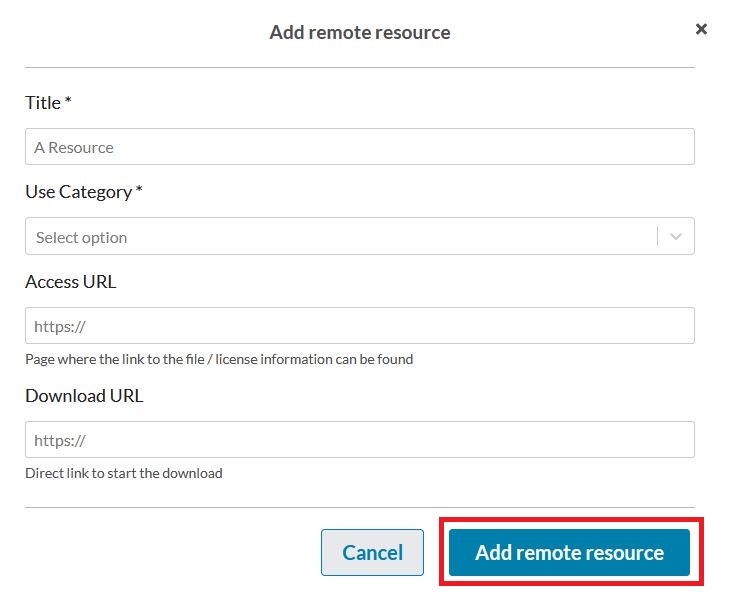
Use a remote resource to link files to the dataset which are not stored in the IDA service. Add the file information one by one by clicking the button “Add remote resource”.

A popup window will open where you can fill-in the information: Give each file a title and a select a use category from the drop-down menu. It’s also recommended to add either an access URL (link to the page where the link or license information is) or download URL (direct link to download the file) to each file. In the “Access URL” field, you can enter the address of a web page that describes the file or its license. In the “Download URL” field, you can enter a link that, when selected, will start the file download immediately. Files from a remote resource are not saved to Qvain or Etsin, but are downloaded by the user from the specified remote location.
After you have filled in the information related to the remote resource, press the “Add remote resource” button. The added source will then appear under “Remote resources”, and you can edit or remove the sources from the same list, if necessary.
LISENSE AND ACCESS TYPE
Lisense *
The license defines how the data in the dataset can be used (metadata is automatically CC0 licensed). The recommended and default license for research data is CC BY 4.0 (Creative Commons By Attribution version 4.0). The license information is mandatory. Most common licenses are available. If you do not find the right license for your dataset, you can choose either “Licence Not Specified” or instead of selecting a value from the drop down just type-in the URL to an existing license page.
Access Type *
This field defines how the data in your dataset can be accessed. Whichever option is selected does not affect the visibility of the dataset’s description (metadata) itself. Even if access to data is restricted, descriptive information about the published dataset is displayed in Etsin.
- Open: Anyone can download the files attached to your dataset.
- Embargo: Anyone can download the files attached to your dataset from a certain date onwards. If you leave the date empty, the data cannot be accessed at all. If you select “Embargo”, a field will appear on the form where you can specify when the embargo will end (the data will be available from that time onwards).
- Requires Login in Fairdata service: Users logged in to Fairdata services can download the files attached to your dataset (currently requires authentication with either Haka ID or CSC account).
- Restricted use: Files attached to your dataset cannot be downloaded at all.
If you select any other option than “Open”, the form will display the following additional fields:
- Data visibility: When the above-mentioned “Access Type” determines whether the material can be downloaded, with this field you can restrict whether even the metadata of the files is shown to the user or not. This metadata includes the names of directories/files with their directory structure, the size of individual directories and files, as well as any additional descriptive information entered about the files (e.g., file type). By default, metadata is shown (even if the actual downloading is restricted by Access Type), but here you can restrict it to be hidden.
- Embargo expiration date: This field is displayed if you selected “Embargo” as the Access Type. Enter the date on which the embargo will expire. After this date, the data will be freely downloadable. If you have also restricted the display of file-specific metadata (see previous bullet point), that restriction will also expire when the embargo ends.
- Restriction Grounds: Specify the reason why access has been restricted. This information will also be displayed in Etsin.
Access rights description
A description related to access rights displayed in Etsin. Here you can provide the user with more detailed information about the terms and limitations related to the data access, or for example, to the license.
TITLE, DESCRIPTION AND OTHER BASIC INFORMATION
Title *
Title for you dataset. It is possible to add a title both in Finnish and in English. You must enter a title in at least one language.
Description *
Description for your dataset. It is possible to add a description both in Finnish and in English. You must enter a description in at least one language. Description text’s formatting supports most parts of Markdown syntax (https://www.markdownguide.org/basic-syntax/).
You can, for example, include the following information in the free-text description:
- Implementation and subject(s) of the research
- Method of data collection and the tools used, and other information related to data collection
- Structure of the data and also descriptions of the variables used
- Note: you can also include descriptive files, such as README-type files, among the files linked from IDA
Issued Data *
Date of formal issuance (publication) of the resource. This value does not affect or reflect the visibility of the dataset itself. If left empty, the current date is used as a default value.
Keywords *
Free-text keywords for your dataset. Please enter at least one keyword. Keywords affect how your dataset can be found in Etsin. You can enter multiple keywords at the same time, separated with commas (,). Click Enter or select “Add keyword” to add keywords.
Subject Headings
Select subject headings for the dataset from the drop-down menu. Qvain suggests subject headings as you type text in the field. You can choose subject headings from the KOKO ontology maintained by the Finnish thesaurus and ontology service Finto, which also has English and Swedish translations of the terms.
Field of Science
Select a field of science for your dataset from the drop-down menu. You can add multiple fields of science. Qvain uses the Ministry of Education and Culture’s official fields of science classification.
Dataset Language
Select the language of the dataset. You can add multiple languages. You can choose from languages in the ISO639-3 code.
Other Identifiers
If your dataset already has a permanent identifier (usually a DOI) created in another service, enter it here. It will appear as a link in Etsin. NB! Qvain automatically generates a permanent identifier (URN or DOI) for your dataset. Enter the identifier here only if the dataset already has an identifier generated elsewhere.
Additionally, if you want to link files stored outside of Fairdata Services, use the “Remote resource” links.
ACTORS
Added Actors: Persons or organizations involved in the research or production of the dataset. A single actor can have several roles. At least one “Creator” and one “Publisher” must be added to the dataset. You can add actors by clicking the “Add new actor” button.
Be careful when adding actors. Take into account aspects such as copyright and ownership, as well as what has been agreed upon contractually and/or otherwise during the research project regarding citations and the mention of author roles.
- First select the actor type: either a person or an organization.
- Then select the roles the actor has. You can select multiple roles if the actor has more than one role in the research or production of the dataset.
- Fill in all other relevant details.
- Person name should be give as Firstname Lastname
- Organization information is mandatory if the actor is a person.
- Use, if possible, identifiers (PIDs), for example ORCID or organization code.
- If the organization is selected from Qvain’s drop down field, it automatically has a valid organization code
- If you give an email address to an actor, Etsin users are able to send messages via Etsin without seeing the actual email address.
Available Actor Roles
Creator * |
A person or organisation who originally produced the dataset. |
Publisher * |
Actor that has permission to publish the metadata and/or data. Usually a research organization. |
Curator |
A person (or organisation) who is responsible for ongoing maintenance of the dataset and keeping it available. Data curators are specialists who collect, organize, clean and transform data to make it accessible for organizations and individuals. |
Rights Holder |
A person or organisation who holds the copyright, neighboring rights or moral rights of the dataset; usually the author of the data or the organization of the author. |
Contributor |
Any other person or organisation that has contributed significantly in the creation of the dataset (not quite creators but assisted in the process of creating the dataset). |
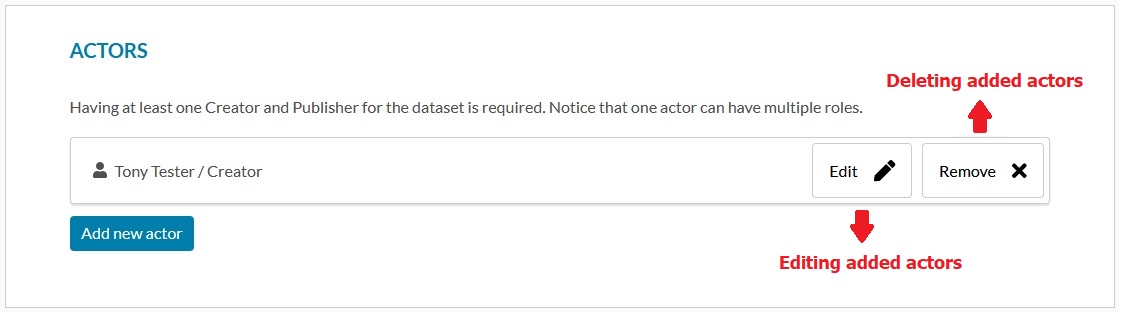
Updating or deleting an Actor
You can edit or delete added actors by clicking the edit and delete icons (see image below).
RELATED PUBLICATIONS AND OTHER MATERIAL
Publications: Refer to publications that are relevant in understanding this dataset. You can either enter the publication information manually or search for the publication in the Crossref Service (crossref.org) using the search function.
Other materials: Refer to other material that are relevant to this dataset.
The relation types you can use when referring to other materials
| Cites / Is cited by | The dataset cites / is cited by other material |
| Is supplement to | The dataset is a supplement to other material (this dataset uses some material as its’ background) |
| Has next version / Has previous version | The dataset is next / previous versio of the other material |
| Has part / Is part of | The dataset has part / is part of the other material |
| Is compiled by | The data is compiled by the other material |
| Is identical to | The data / dataset is identical to the other material |
| Continues | The dataset supplements / continues the other material |
| References | The dataset references to the other material |
| Is variant form of | The data / dataset is same but for example in different format than the other material |
| Was derived from | The data / dataset is derived from the other material |
| Relation | Any other relation between the dataset and the other material |
GEOGRAPHICAL AREA (SPATIAL COVERAGE)
Area covered by the dataset, e.g. places of observations.
You can add multiple areas. When adding a geographical area, the area name is a mandatory field. In addition, you can add an address, search for the location from the YSO place ontology, and add the area’s geometry and the location’s altitude.
TIME PERIOD (TEMPORAL COVERAGE)
Time span that is covered by the dataset, e.g. period of observations. You can add multiple periods. The period is added by clicking the “Add temporal coverage” button. You can enter the information either by selecting a time period from the calendar or by entering the start and end dates directly in the fields in the format “dd.mm.yyyy”, e.g. “23.03.2021”.
INFRASTRUCTURE
Services or tools that are used to produce the dataset.
Note! At the moment infrastructures cannot be selected. New infrastructures will be taken into use as soon as possible and they will be integrated with Research.fi.
HISTORY AND EVENTS (PROVENIENCE)
Event or activity that was the subject of the dataset.
PROJECT AND FUNDING
A project in which the dataset was created.
Project name
The title or name of the project. It is possible to add a title both in Finnish and in English. You must enter a title at least in one language.
Project Identifier
An unambiguous reference to the resource within a given context. Recommended best practice is to identify the resource by means of a string conforming to a formal identification system.
Participating organizations
Organization(s) which are participating in the project. You can select an organization from the drop-down menu or enter the organization information manually.
Funder Organizations
You can select a funding organization from the drop-down menu or enter the information manually. Organization whose funding and resources were used to produce the data.
Funding Type
You can select the funder type of the dataset from the drop-down menu.
Funding Identifier
Unique identifier for the project that is being used by the project funder.
Note! If the dataset is going to be Digitally Preserved in Fairdata Digital Preservation Service, there are additional mandatory fields:
- Name (filename as a default) and Use Category for each file
- For CSV file: fileformat text/csv (if not specified, the files are processed as text/plain), character encoding and technical delimiter
- For text files it’s also recommended to specify the text encoding (if not specified, the service will try to determine it but it’s not 100% reliable)