Content
- Fairdata Services in General
- IDA – Research Data Storage
- Etsin – Reseach Data Finder
- Qvain – Research Dataset Description Tool
- Metax – Metadata Warehouse
- Digital Preservation Service for Research Data
1.Fairdata Services in General
Taking care of your research data is an essential part of good scientific practice. Fairdata services are made to ease this task.
The Fairdata Services are integrated services for storing, sharing and publishing research data. The Fairdata service components are IDA for storing research data, Qvain for creating metadata descriptions for datasets, the metadata warehouse Metax, the research data finder Etsin, open data publishing platform AVAA and the Digital Preservation Service for Research Data. The services are offered free of charge to Finnish universities, universities of applied sciences and state research institutes. Digital preservation service is based on agreement.
The services are not tied to a specific field of science. The storage space in IDA can be shared among the project members, enabling e.g. collaborative projects to utilise a shared storage space to prepare their data for publication. Data stored in IDA is included to dataset descriptions using the Qvain metadata tool or Metax end user API and published in Etsin. Published data can be found by others as it has a persistent identifier enabling linking from e.g. related publications. Read more about the benefits of the Fairdata services.
The data and information stored in the services is stored in Finland. The Fairdata services are provided by the Ministry of Education and Culture and produced by CSC – IT Center for Science Ltd.
All of the service components are available for end-users. The renewed IDA, Metax and Etsin were deployed 2018, Qvain in July 2019 and Qvain Light in August 2019. In November 2020 the metadata tools Qvain and Qvain Light were combined to one tool, called Qvain. Advanced users can use also Metax end user API to create dataset descriptions (latest version, Metax API V3, was fully launched in February 2025).
Updates about the services are available in Finnish in the News section of Fairdata.fi and in Bluesky.
The services are available to researchers and other actors in all higher education institutions and state research institutes in Finland. The services are also available for collaborators. The services are offered free of charge and they’re dedicated for research purposes. Read more about the use policies.
Dedicated contact persons in user institutes support their end users and act as contact points toward CSC Fairdata service support.
To use the IDA storage service the end user needs to create or be a member of a CSC project with a IDA storage space allocation. The researcher’s home organisation’s IDA contact person grants the project the IDA storage space. Read more about how to become an IDA user.
The Digital Preservation Service for Research Data is meant for the digital preservation of research datasets (data, publications, code, learning materials etc.). Read more about how to become a partner organisation with the Digital Preservation Service for Research Data.
In brief: If you want to use only Qvain or Metax API to create metadata descriptions, self-registering the CSC customer account online is sufficient, and no additional measures are needed to start using the services. Self-registration can be done in a couple of minutes in CSC’s MyCSC Customer Portal. In addition to creating a CSC customer account, IDA requires either creating or joining project group and an online IDA storage space application. Etsin is open for everyone without registration.
Full guidance: Registration as a CSC customer account is required to use IDA, Qvain and Metax API. If your home organisation provides you a Haka or Virtu ID, you can simply register as a CSC customer in CSC’ MyCSC Customer Portal with your own Haka/Virtu credentials. If you don’t have a Haka or Virtu ID provided by your home organisation, you can apply for a CSC account by contacting servicedesk@csc.fi. After registration, logging in to the services is possible with your Haka, Virtu or CSC customer account.
To use IDA for storing or publishing research data (files), you need to have a CSC customer account as described above. In addition to this, you need to be invited to an existing CSC project, or create a new CSC project for which the IDA storage quota can to be applied to. All this can be done online in the CSC customer portal. The IDA storage quota is available after your application has been approved by your organisation’s IDA contact person (usually within a few working days). Detailed instructions can be found at https://www.fairdata.fi/en/ida/becoming-an-ida-user/. If your home organisation doesn’t have a named IDA contact person yet, please contact your home organisation’s research services before applying for IDA space.
The dataset metadata published in Etsin are open for all without registration. If you’re interested in the Digital Preservation Service for Research Data, please contact your home organisation’s research services.
Yes. Every project in IDA has a responsible Project Manager, who can apply for a project membership for a collaborator abroad. All members of a project that uses IDA can create dataset descriptions using Qvain or Metax API.
A persistent identifier or PID is a unique and unambiguous machine readable name for an object, in this case a specific research dataset. It is also a permanent link, that will always take you to the landing page of the dataset, where the description and for example the license of the dataset can be found. Usually a PID is a DOI or a URN, identifiers provided by two different systems and they can be recognized by the first letters as either.
When your dataset has a PID, which it is allocated by the Fairdata services, you can use it in data citation. All citations can be traced back to you and the link will always take you to a landing page, even if the data is not available or the services have moved or changed over time. Using persistent identifiers is one of the corner stones in the FAIR principles.
If the dataset is available from a source that is outside the Fairdata services, you can create a dataset using Qvain and get a URN for the landing page in Etsin. When the data is outside Fairdata services, you are responsible for the integrity of the data yourself.
Editing the metadata of a dataset that has been already published with Qvain does not create a new PID for the dataset. However, changing the files or folders included to the dataset requires creating a new version of the dataset, with a new PID. An exception to this are cumulative datasets to which files can be added. A new PID is allocated when the data included to the dataset changes to ensure data integrity. A PID is a promise, and it should always give the user a possibility to access or at least find information about a specific dataset. Always consider reproducibility.
If you delete (or unfreeze) files linked to a published dataset in IDA, the published dataset is shown as deprecated in Etsin, because the files originally linked to the published dataset are no longer available. If you wish, you can create a new version of the dataset and link new files to it. The landing page of the new version and files linked to it will be shown in Etsin normally.
We provide support and training for data management and the Fairdata services for both researchers and data management experts. On our service-specific pages you will find user guides and tutorial videos to guide you through the use of the services. We organize webinars as well as training sessions of which you will find preliminary information about Fairdata training here. Recordings of previous webinars and trainings are also available. The data management checklist provides you support for the whole research data life cycle. More information about digital preservation and related training events can be found at digitalpreservation.fi.
The Fairdata demo environment is available for temporary testing and demoing of the Fairdata Services. Read more about the Fairdata demo environment.
You may also join the Fairdata network, which has been created to enhance the use of Fairdata services. The network aims to improve cooperation and the flow of information between organisations using Fairdata services and CSC (service producer). Participation is beneficial especially for organisations, that already use the Fairdata services or are planning to start using them in the near future. The network has 4-5 meetings per year. Read more about the Fairdata network (in Finnish).
You can always ask for help from CSC Customer Service on weekdays from 8.30 am to 4.00 pm; servicedesk@csc.fi or +358 9 457 2821.
Depends on who you want to share your data with:
- If you only need to share the data within the project group, then you are fine with using IDA only. Everyone belonging to the same project in IDA can access the project’s data via IDA. However, remember that all data in IDA needs to be frozen and included in a dataset, that is published to Etsin, but the access to the published dataset can be restricted.
- If you only need to temporarily share the data for some people who do not have a user account in IDA, you can make temporary links to files stored in IDA. Please see: https://www.fairdata.fi/en/ida/user-guide/#temporary-share-links. These can be used to e.g. review the data.
- If you want to publish the data for “public” and get a persistent identifier (URN/DOI) for your dataset (for example for scientific references), you need to publish it in Fairdata. Just make sure you freeze the files in IDA and then create a dataset description with Qvain (qvain.fairdata.fi). Include your frozen IDA files to the dataset, and publish it to Etsin (etsin.fairdata.fi). Etsin provides a landing page and a persistent identifier for the dataset, and provides download links to the data. You can decide whether the data can be downloaded by anyone, by no one or only by users that log in to Etsin. Read more from the user guide.
2. IDA – research data storage
2.1. General questions about IDA service
Data is stored in IDA continuously, provided that the Terms of Use are met. The Terms of Use require e.g. publishing one or more dataset descriptions of the data stored in the service such that the dataset descriptions are accessible in the Fairdata Etsin service.
Published data (available openly, under embargo, or to logged-in users) can be stored in IDA continuously, without a service-imposed expiration date, even if the CSC project or the user account of the CSC project manager is no longer active. This helps to keep published data accessible even if the researcher who published it for example changes jobs or moves abroad.
Exceptions:
- Data that is not accessible at all via Fairdata services (access in Etsin is marked as “restricted”) requires an active CSC project and a project manager to be stored in IDA.
- If the data contains personal data, a valid personal data processing agreement is required, which in turn requires an active CSC project and a CSC project manager.
More information:
IDA storage quota can be applied for by researchers from Finnish higher education institutes and Finnish research institutes. Use of the service requires the registration of a CSC customer account and an IDA storage space application. IDA storage space is applied online in CSC’s MyCSC Customer Portal. Applications are reviewed by your home organisation’s IDA contact person. After the IDA access is granted, logging in to the IDA service is possible with your Haka, Virtu or CSC account. Read more about the IDA use policy and applying IDA storage quota.
The Project Manager can apply for IDA storage space in CSC’s MyCSC Customer Portal.
- Create a CSC customer account.
- Create a CSC project
- Apply for IDA storage space with an application form in CSC’s MyCSC Customer Portal.
All this can be done online and the storage quota is available after your application has been approved by your organisation’s IDA contact person. Other project members can be added by the Project Manager after they have registered their CSC customer account. Detailed instructions can be found at https://www.fairdata.fi/en/ida/apply-for-ida-storage-space/.
A CSC Project is a group of users that have a right to use a service and who belong to a shared storage space in the IDA service. The CSC Project must have a named person – a Project Manager – responsible for the group access, their data and the service usage (the technical term is CSC Project Manager, read more about the prerequisites and responsibilities). IDA storage quota is applied by the Project Manager and granted to their project group via CSC’s MyCSC Customer Portal. The same project group can use also other services produced by CSC. Read more about CSC projects.
The IDA storage quota is not tied to a a single real-life research project or a specific research grant. In the Fairdata services one project in IDA can produce and publish multiple datasets in Etsin, but the files linked to a specific published dataset can belong only to one project group.
The Project Manager has a certain number of responsibilities; he/she can e.g. add and remove project members. The Project Manager also serves as a contact person between the project and CSC. For these reasons the Project Manager also must have an active CSC customer account at all times. When creating a CSC project it is specifically asked in the application if the person applying can act as the Project Manager, i.e. he/she is an experienced researcher involved in the project, or for example the organisation’s research services staff member. If you have any questions regarding this matter, please contact servicedesk@csc.fi
Read more about the responsibilities of the Project Manager from General Terms of Use for CSC’s Services for Research and from IDA Storage Service Terms of Use.
The Project Manager can add and remove members in the CSC’s MyCSC Customer Portal. The instructions to add and remove project members can be found at https://www.fairdata.fi/en/ida/apply-for-ida-storage-space/#adding-members.
Most likely yes, read more below. If your home organisation changes, please contact servicedesk@csc.fi and we’ll update your customer account or advice in creating a new one.
If the Project Manager’s home organisation changes:
The project using IDA needs to have a Project Manager, who is affiliated to an organisation that is entitled to use IDA. If the Project Manager’s home organisation changes, the options are to name a new Project Manager to CSC, or to think whether the IDA space should be also moved under another organisation in IDA. In either case, please contact servicedesk@csc.fi.
If a CSC project member’s home organisation changes:
The Project Manager defines who are entitled to be project members. All IDA users need to be eligible to have a CSC account. The use of the project’s IDA storage space is not tied to a single organisation, so the Project Manager can also have people from other organisations as project members. If a user’s organisation changes they should contact servicedesk@csc.fi to update the customer account or to create a new one.
A foreign research associate working in the Finnish research system can be given access to IDA as a project member, if the project is working under a Finnish higher education institute, state research institute or another entity entitled to use IDA. The manager of the project that uses IDA can decide which users can access the project’s IDA space. Read more about CSC account policy for foreign research associates.
IDA is meant for research data. A student can be a member of a project using IDA, when the student produces research data or when access to research data is needed. The project using IDA needs to have a Project Manager who is an experienced researcher involved in the project or e.g. a project manager or a technical coordinator for a collaboration project. IDA is not meant for students, who produce and save data only for a thesis.
The new Project Manager must have a CSC account and they must be a member of the project.
The new and the old Project Manager should then together contact the CSC Service Desk (servicedesk@csc.fi) and ask for the Project Manager to be changed.
The owner of the data defines its access rights and using IDA does not change the ownership of the data. Although the IDA storage space is granted by an organisation, agreements on the ownership of the data should be made separately and quota granter organisation doesn’t automatically have rights to the stored data. It is recommended to make agreement on the rights to the data early on, e.g. what happens when someone leaves the project.
2.2 Questions about using IDA and the data stored in IDA
In IDA it is possible to store all kinds of research data: new research data, as well as published research data. IDA is meant for storing stable research data, which can be constructed and described as research datasets. The service is not optimized for data under heavy usage (e.g. computing disk data, data used in web applications). It is either not ideal to connect IDA directly to an instrument that constantly pushes data onto the disk. What is relevant is how IDA is used, not what kind of research data is being stored. However, IDA is not designed for storing sensitive data. For this kind of data, CSC provides SD services.
Correctly anonymized data is suitable for IDA. Read more on personal data and its anonymisation in Finnish Social Science Data Archive’s data management guidelines: http://www.fsd.uta.fi/aineistonhallinta/en/anonymisation-and-identifiers.html. Please note that there are special requirements for handling personal data in research.
The most suitable user interface for you depends on your skills, needs and the computers you are using. The browser user interface at https://ida.fairdata.fi/ is easy to use and it doesn’t require installing new software.
The command line tools can be used with Linux/Mac operating system an are suitable for transferring large files. Notice, that freezing files is not possible with command line tools and it need to be done via browser interface. Read more about the command line tools: https://www.fairdata.fi/en/ida/user-guide/#command-line-tools
The full user guide is available at https://www.fairdata.fi/en/ida/user-guide/.
With the metadata tool Qvain, data stored in IDA can be described as a dataset, set as openly downloadable and published in Etsin. Your published dataset will get a persistent identifier and a landing page, enabling citations. Multiple files and folders can be linked to the dataset, but the files linked to a specific dataset can belong only to one project group in IDA.
You can also set files/folders downloadable from IDA with temporary share links, see the guide: https://www.fairdata.fi/en/ida/user-guide/#temporary-share-links.
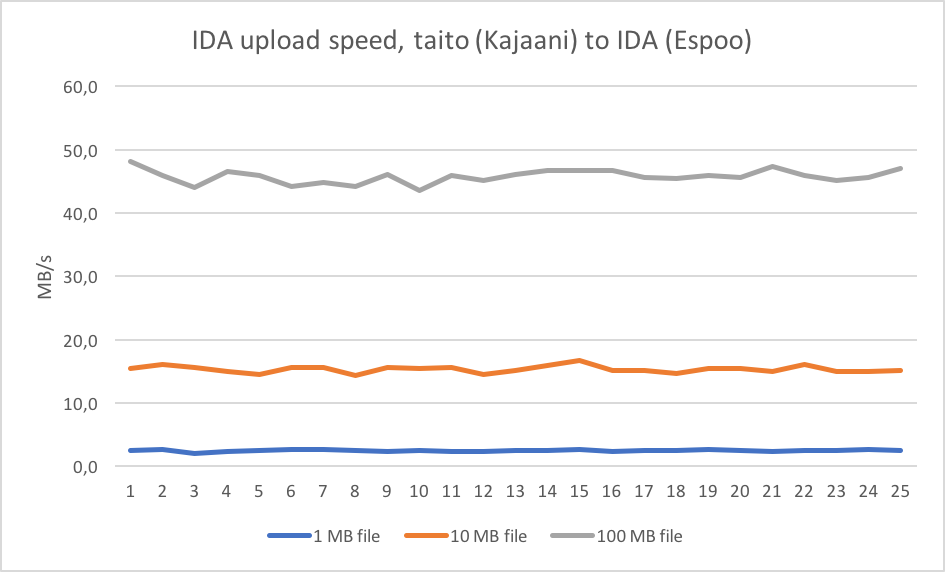
This picture gives an example of how file size affects the speed of the transfer.
{kind=link}
The IDA CLI tools are available to you on Puhti and Mahti, and can be used for uploading, modifying, and downloading content in the staging area as well as downloading content in the frozen area of your project.
Example: To download a particular file from the staging area of project 2001234 with the relative pathname ‘/somefolder/somefile.txt’ to the local filename ‘file_on_puhti.txt’ in the current directory on Puhti, you would use the command:
ida download -p 2001234 /somefolder/somefile.txt file_on_puhti.txt
The IDA CLI tool will prompt you for your IDA credentials (if you have not already defined them e.g. in your .netrc file).
Example: To download a particular file from the frozen area of project 2001234 with the relative pathname ‘/somefolder/somefile.txt’ to the local filename ‘file_on_puhti.txt’ in the current directory on Puhti, you would use the command, including the parameter ‘-f’ to indicate that the relative pathname corresponds to the frozen area of the project:
ida download -p 2001234 -f /somefolder/somefile.txt file_on_puhti.txt
See the online IDA CLI guide for more details about what you can do with the CLI tools and for additional examples of the most common operations.
IDA is a specialized service for the secure storage of research data, and not just a simple cloud storage solution. The purpose of the dedicated CLI tools is to simplify the transfer of data to and from the service for the user, while still ensuring that essential validation and other housekeeping tasks are properly performed in relation to upload and management of data.
Various checks and other background operations occur when uploading and managing data in the service, whether using the CLI tools or the web UI, which would not happen if the service behaved merely as a cloud storage solution mounted and interacted with as a basic filesystem.
You can use the validate command in IDA’s command line tools (https://www.fairdata.fi/en/user-guides/user-guide/#command-line-tools) to verify that the file stored in IDA matches the size and checksum of the file in your local storage. See more here: https://github.com/CSCfi/fairdata-ida-v3/tree/master/cli#validation. Check out also video tutorial Uploading and Validation of Data.
File details (size, checksum) can also be viewed from IDA’s browser user interface. To view the details of a particular file, navigate in the files view to where the file is located and click on the ellipsis menu (…) to the right of the file name. Then select “Open details”. This will open a tab on the right side of the view. The file details will be shown at the top of the tab.
You can click the pending action to see more information. If there is a timestamp for “File Metadata Stored”, you can go ahead and include the data in a dataset description in Qvain. The next stage of the action, File Replication, will finish in the background in IDA.
3. Etsin – Reseach Data Finder
Etsin is primarily developed for researchers but the service is open for everyone at etsin.fairdata.fi. Anyone can search for datasets and the published metadata on the dataset is open for everyone to see. The data owner decides how the underlying research data can be accessed and by whom.
Etsin shows information about the datasets and metadata in the Finnish national Fairdata services. Datasets can be created via Qvain Metadata Tool or with Metax End User API. In order to use those services you need to be registered as a CSC customer (registration can be done in CSC Customer Portal.
Organizations can also bring descriptive metadata of their already existing research datasets to Etsin (more information in Finnish can be found here).
All dataset metadata Etsin uses is stored in Metax, Metadata Warehouse Service.
Note! At the moment metadata is not harvested for external sources (planning has started for new harvesting service in Autumn 2025).
Harvesting means that the metadata (dataset) is originally stored somewhere else (external repository) and the master landing page is not in Etsin but in an external service. By following pre-agreed mappings and set of harvesting rules the information about datasets can be fetched into the metadata repository Etsin uses (Metax, Metadata Warehouse Service) and is then (after agreed validation process) findable via Etsin. A link from Etsin will then take the user from Etsin to the master landing page of the original source.
Organizations can use Metax REST API to push datasets into Metax (this possibility can already be taken into use). Additional information (only in Finnish): Metax integration for organization.
To have the organisation’s datasets harvested or pushed with Metax API the following topics should be discussed and agreed upon (to be done as a project together with the Customer):
- Customer’s right to deliver the metadata (license, personal data) and responsibility regarding the data quality
- Harvesting protocol (preferably OAI-PMH) and APIs (source organisation should have an API that communicates with CSC’s API)
- Harvested datasets should have Persistent Identifiers in the source repository
- Mapping and refinement of metadata
- Metax data content (only in Finnish)
Please contact the CSC Service Desk (servicedesk@csc.fi) if you are interested or would like to have more information on having metadata harvested or pushed into Etsin.
4. Qvain – Research Dataset Description Tool
4.1. General questions about Qvain Tool
Qvain provides an easy way to describe your research data and publish the data stored in IDA. By creating quality metadata to your dataset and publishing it, you make it findable in Etsin and enable reuse of the data. Quality metadata keeps the data findable and citable and ensures that Fairdata services are interoperable. Qvain helps to add metadata that fulfils the minimum requirements for digital preservation.
The files in the Fairdata IDA can be linked to the dataset description, but it is also possible to refer to data sources outside of Fairdata. The user must be a member of an project in IDA to link IDA files to their dataset.
In order to use Qvain you need to be registered as a CSC customer. After registration logging in to Qvain is possible with Haka, Virtu or CSC account.
If you have a Haka or Virtu ID provided by your home organisation, you can register as a customer in CSC’s MyCSC Customer Portal with your own Haka or Virtu ID. If you don’t have a Haka or Virtu ID provided by your home organisation, you can apply for a CSC account by contacting servicedesk@csc.fi.
4.2 Questions about using Qvain and the metadata saved in Qvain
CSC performed a migration operation to transfer all published datasets from old Etsin (etsin.avointiede.fi) into new Etsin (etsin.fairdata.fi). These already existing datasets will then be updatable also in Qvain. Migration toon place in the end of June 2019, just before opening the Qvain metadata tool.
Updating the datasets in old Etsin is not possible after the migration.
The Fairdata services offer the possibility to publish data so that they are findable, accessible, interoperable and reusable. However, this requires some input of the curator and the researchers. Before publishing, it is good to consider the following things:
- When publishing data in the Fairdata services, the data needs to be licensed. Licensing is always recommended. The license is not the same thing as access, instead it states how the data can be used. Check your funder’s and research organization’s policies and other relevant documents. Ideally, all this should be documented in the data management plan and in contracts. Generally, the recommended license for research data is CC-BY 4.0. All metadata is open data, i.e. CC0. If you are uncertain, discuss with your data support or library.
- Find out about and/or agree upon which agents are documented as creator, publisher, curator. There can be only one publisher. It should preferably be an institution. The curator is the party that is responsible for taking care of the metadata and data, and that can give more information about the data and answer questions about access and licensing. This information should be kept up to date at all times!
- If you do not have an ORCID, register one. Always use it to ensure credits.
- Other mandatory information and things to consider are access and important elements that support findability and reuse, i.e.
- the title of the dataset should be unique and descriptive
- the description should be extensive enough to enable reuse
- the keywords are important for findability. Use relevant domain specific terminology.
- several fields of science can be added
- Arrange your files and folders carefully. Use unique file and folder names. If the data is in IDA, freeze it. Double check you don’t include data that cannot be published. All personal information should be excluded from file names etc.
It’s not mandatory. Qvain can be used independently of the file storage service. Depending of the user’s needs, there are tree options:
- Using Qvain to create and publish only the metadata of a dataset. Adding data is not mandatory.
- If the user is also using the IDA service, selected files stored and frozen in IDA can be easily described as a dataset with Qvain. The dataset’s describer decides whether the data can be freely downloaded via Etsin or whether there are restrictions. Etsin shows the files in their folder structure, which is useful when the dataset consists of multiple files.
- Third option is to use Qvain to create and publish a dataset which links to a remote web resource. The user can also define a download URL for the remote resource in Qvain.
Read more about versioning rules in the User Guide.
Qvain shows the datasets which you have created yourself or to which you have editing permissions. Datasets created in old Etsin or via Metax API should also be visible in Qvain. If you encounter any issues, please contact servicedesk@csc.fi.
When you save a dataset in Qvain it does not affect the published dataset. Saving the dataset only saves it as a draft. Only when you Publish the dataset are the changes visible in Etsin.
Be careful when changing the already published dataset! After the metadata has been published all changes in the data should be clearly documented in the metadata or a new version of the dataset must be created and stored. The owner of the dataset is responsible for not compromising the repeatability or reproducibility of the research.
Note! If you have attached files to your published dataset from IDA, you will not be able to delete or add files to your dataset without first making a new version of it. (The exception to this are cumulative datasets to which files can be added.) After publishing the new new version, Etsin will show the newest version by default and you will see other versions under that. In Qvain’s My datasets -view all versions are shown as individual datasets.
Read more about versioning rules in the User Guide.
If you wish to add/remove files to/from the published dataset a new version has to be created first. This is to guarantee the repeatability or reproducibility of the research. Etsin will always show the newest version by default and you will see other versions under that.
Note! After the metadata has been published all changes in the data should be clearly documented in the metadata. The owner of the dataset is responsible for not compromising the repeatability or reproducibility of the research.
Yes. You can publish your dataset without any data, with just descriptive metadata, and thus get a persistent identifier (DOI or URN).
It’s important to remember that even if the metadata is published without any data, the data source still needs to be selected and it cannot be changed later. This is mandatory for Qvain to be able to store the possible data later. So, if you want to publish only the metadata first, and then add data from IDA later, you should make sure that IDA is selected as a data origin before you publish your dataset for the first time.After the metadata has been published (i.e. when the persistent identifier has been set), data from IDA can be added ONCE without the need to create a new version (with a new persistent identifier).
Read more about versioning rules in the User Guide.
When the data origin is a remote resource, the URL pointing to the data can be changed without having to create a new version of the dataset.
5. Metax – Metadata Warehouse
Metax is mostly invisible to the end users. It is the metadata storage for the Fairdata Services. The data model is based on DCAT and it’s compatible with Datacite.
Metax does not have a graphical UI. Most of the API’s provided by Metax are accessible only to other Fairdata services, and the main method for interacting with Metax should be by using those services. For advanced users, Metax End User API can be accessed directly by using special tokens for authentication.
6. Digital Preservation Service for Research Data
Digital preservation refers to the reliable preservation of digital information for several decades or even centuries. Hardware, software, and file formats will become outdated, while the information must be preserved. Reliable digital preservation requires active monitoring of information integrity and anticipation of various risks. Metadata, which describes for example the information content, provenance information and how the content can be used, has a key role in this.
Research datasets (data, publications, code, learning materials etc.) are eligible for digital preservation, if they are considered relevant to national or the institutional research activities. Both are based on the organisation’s evaluation.
The Common Digital Preservation Services, including Digital Preservation Service for Research Data, are offered and owned by the Ministry of Education and Culture, and are managed and further developed by CSC – IT Center for Science Ltd.
Many trusted digital repositories provide long-term storage of the data exactly as it has been deposited, and guarantee data integrity on the bit level. However, such archiving method will not ensure that the data will be usable and readable in the long term, due to software and file format obsolescence. The aim of digital preservation is to guarantee that especially valuable datasets are still usable for the future generations. Digital preservation is costly: it requires active, ongoing curation and taking measures to extend the data lifetime so that it stays usable for decades or even centuries. Such measures can be for example converting the files from (nearly) obsolete file formats to new, or various means to ensure data integrity and quality, keeping data readable and usable and protecting it from decay and damage in the long term.
Partner organization refers to an organization, department, or other entity using the Digital Preservation Service for preservation of digital content. For more information, see https://www.fairdata.fi/en/about-fairdata/becoming-a-partner-organisation/.
Datasets transferred to digital preservation are those, which have value for the organisation or on national level in the long term. Organisations evaluate their needs for digital preservation themselves. For example the following characteristics could be considered:
- The dataset’s potential for reuse
- Unique data whose generation or collection required a lot of resources; irreplaceable research that would be extremely difficult, costly, or impossible to reproduce
- Data resources that are considered fundamental to national or the institutional research activities.
Digital preservation services define the policies and technical specifications necessary for data preservation in collaboration with organizations. The information includes:
- Sufficient metadata that make the data comprehensible
- File formats that are open and readable by more than one application and facilitate reuse of data
- Clarification of ethical and legal issues such as IPR or personal (sensitive) data issues
Partner organization proposes the dataset to be preserved to the Ministry of Education and Culture, which grants a certain quota for the dataset.
There are several options for doing this. For more information in Finnish, see https://digitalpreservation.fi/user_guide/packaging.
For more information, see http://digitalpreservation.fi/.
If you have any questions about particular features, or any other issue relating to the services, please contact CSC customer support at servicedesk@csc.fi